Bioinformatics to Facilitate the Understanding of Complex Biology
We are constantly updating our toolbox of statistical and visualization methods to bring forward the full biological potential of your data. Our team of bioinformaticians has years of experience building bespoke solutions for customer data projects. When the need arises, we create new analysis modules based on state-of-the-art research to accommodate every aspect of data exploration.
We believe reproducibility is a central pillar of the scientific process. To that end, we walk you through our entire methodology for data analysis, making sure to highlight any assumptions, parameters, and specific algorithms employed toward reaching concrete biological conclusions. We pride ourselves on delivering clear, concise, and comprehensive results as a final product.
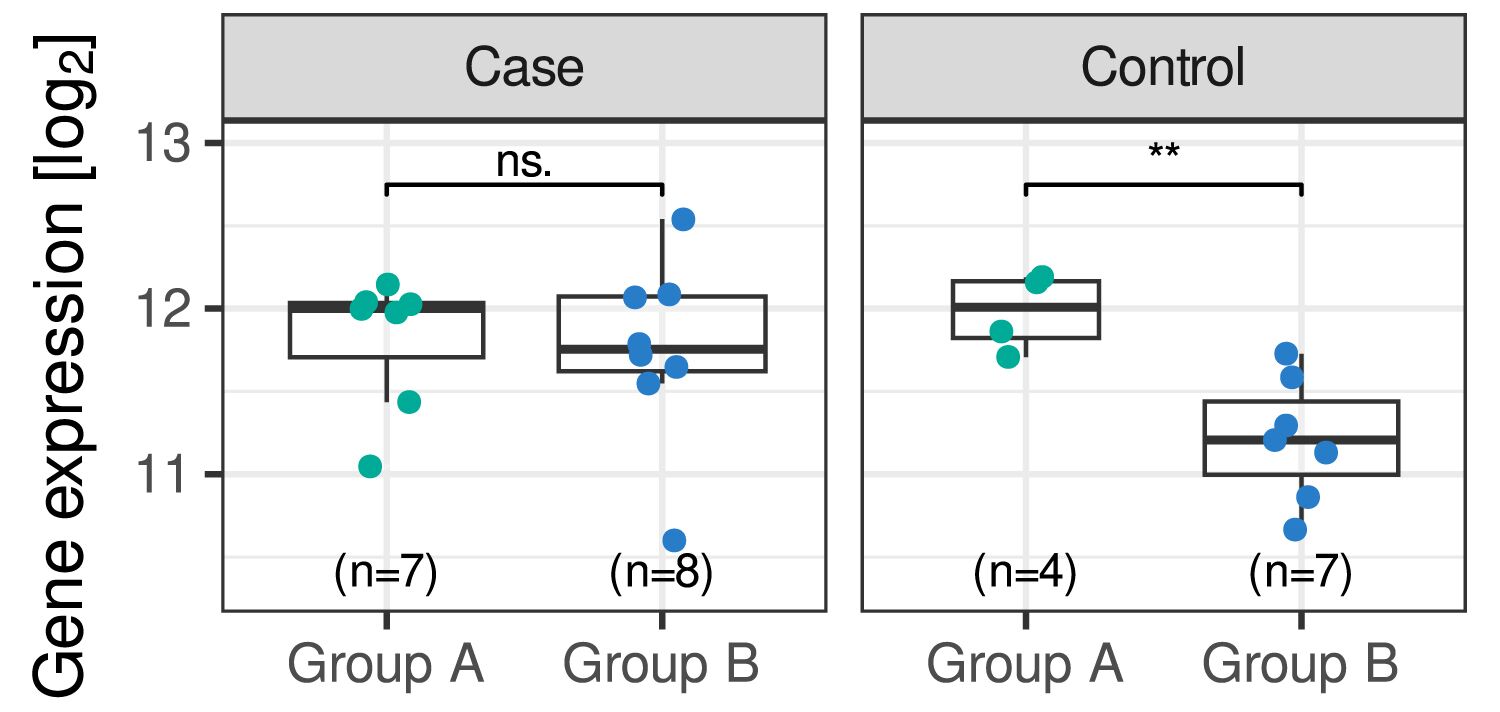
Transcriptomics, Genomics, and Epigenomics
We offer next-generation bulk and single-cell sequencing data analysis as a stand-alone or fully integrated service. In-house data are generated at our next-generation sequencing facility, starting from preclinical or clinical material. We are also a certified service provider for 10x Genomics single-cell sequencing.
We have established analysis workflows for:
- single-cell and bulk RNA sequencing
- whole-exome sequencing
- whole-genome sequencing
- ChIP-seq
- ATAC-seq
- B- and T-cell receptor profiling
- CITE-seq
- CRISPR barcode sequencing
- transgene (AAV, LNPs) barcode sequencing
- Nanostring GeoMX spatial profiling
These workflows incorporate the latest top-performing publicly available tools and proprietary programming solutions that cover all steps of the data analysis, starting from quality control of the raw data up to the statistical analysis of the biological entity data.
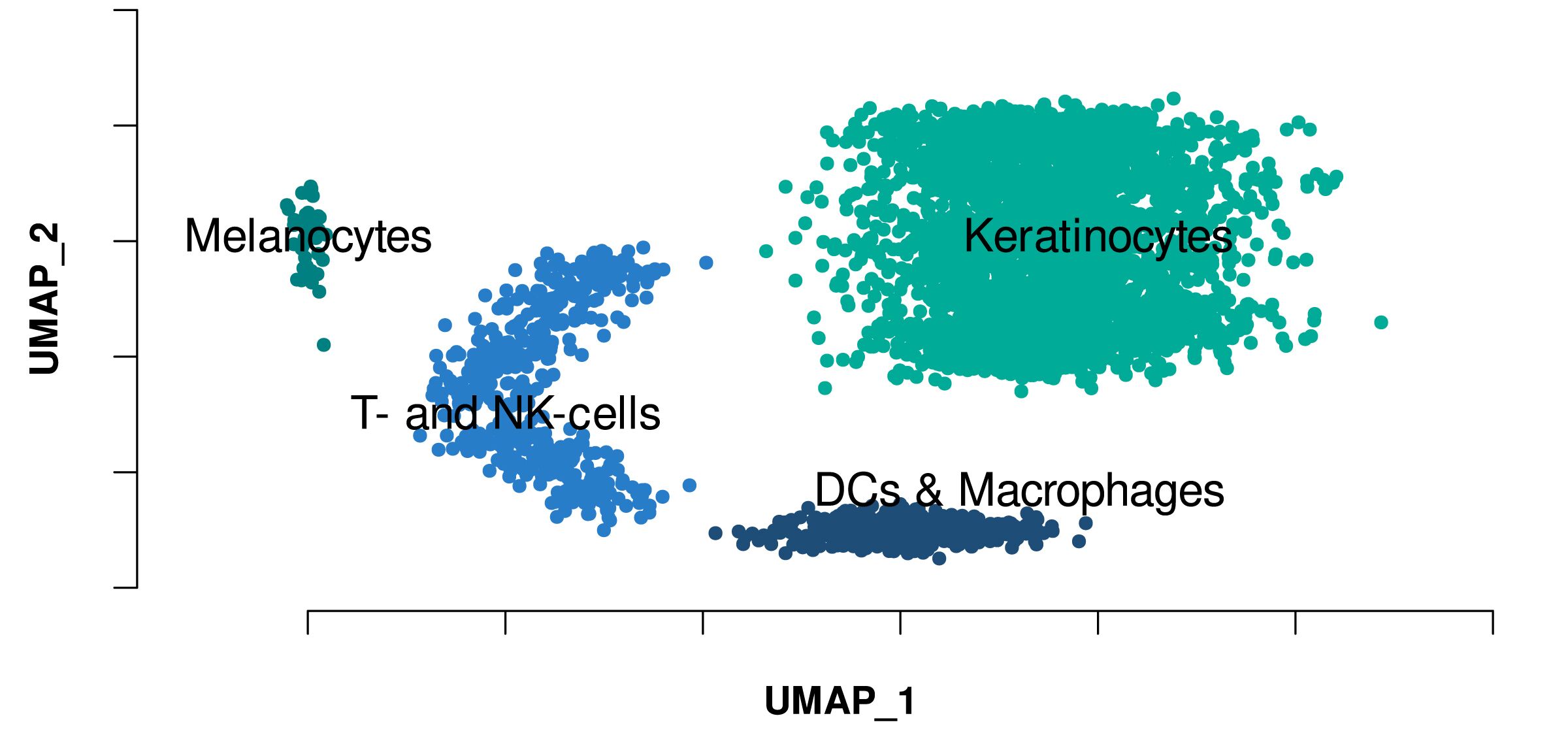
Example UMAP plot showing the clustering of single-cell RNA sequencing data. Labels indicate the predicted cell type of each cluster, based on similarity to reference gene expression profile.
Bioinformatics Analysis Packages
We offer a standard bioinformatics package that consists of adaption of the appropriate workflow for your project, followed by the packaging and transfer of all generated results and preparation of a comprehensive summary report that will bring forward all relevant aspects of your data. The files that you receive from us will enable you to get the most out of the precious data generated from your experiment.
Furthermore, we also offer an advanced analysis package that contains all aspects of the standard package described above plus a thorough deep dive into your data to bring you even closer to answering the biological questions that you had in mind when planning the experiment. The advanced package is custom-tailored to each project.
As an example, see here for more details about how we typically analyze the transcriptome readouts of RNA-seq experiments.
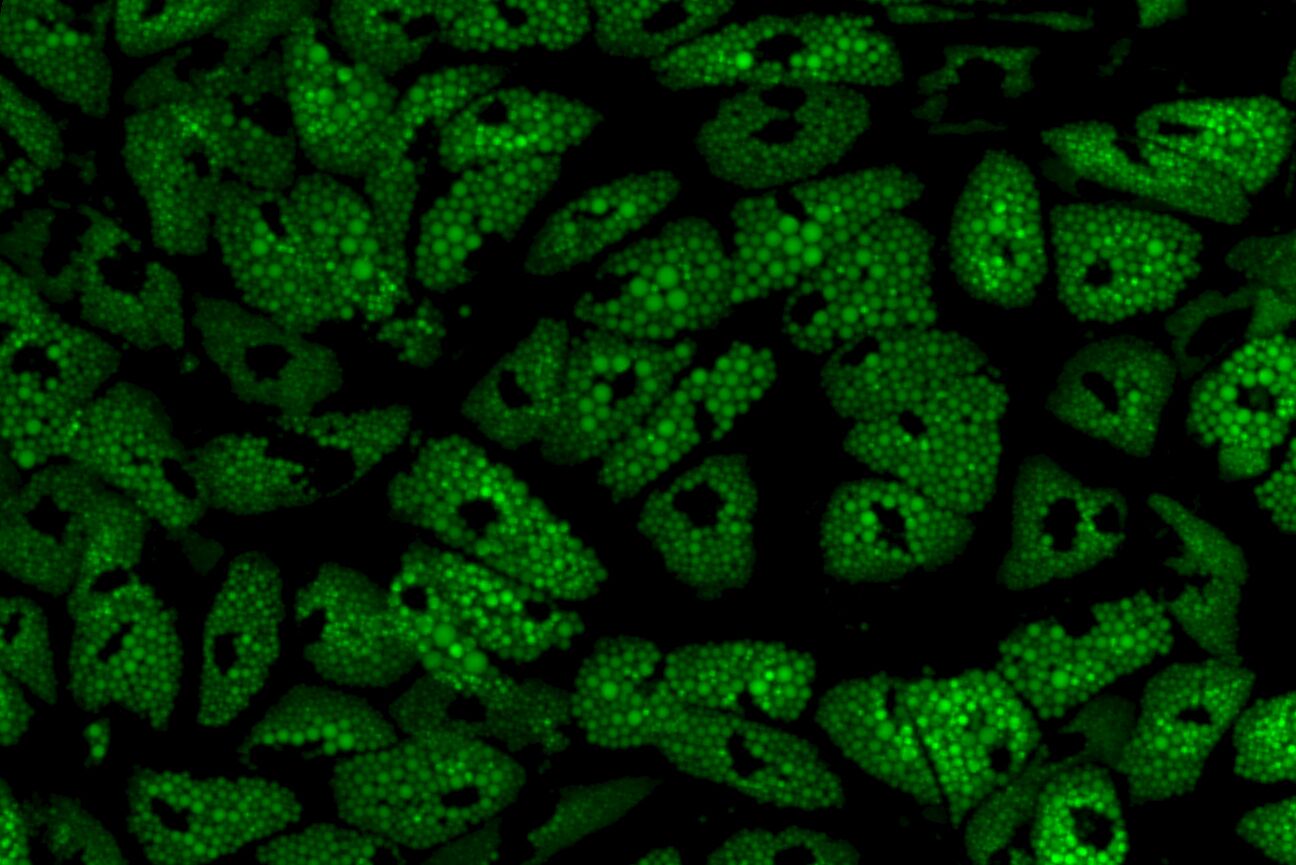
High-Content Cellular Assays
- Fully customizable microscopy image analysis at single-cell resolution
- Single-cell CRISPR screen evaluation
In Silico Target and Indication Space Evaluation
- We employ literature and database mining in combination with machine learning algorithms to identify novel associations and expand known ones between drugs, targets, and disease areas.
- Predicted associations can be experimentally validated in-house.

Example excerpt of literature-derived knowledge graph for the query ‘ALK inhibitors for treating neuroblastoma’.
